目录
简介
在常用的系统设计中,我们经常需要对系统能力和性能进行估算,因此我们需要熟悉一些常见的性能指标结合,来得出一些估算值,这些值会使得我们对系统的设计有初步的一些认识。
一、常用的封底估算
1. 2 的幂
在面对分布式系统的时候,尽管数据量可能会十分庞大,但归根结底还是数学运算,为了获得正确的运算结果,了解 2 的幂所代表的数据量单位是非常重要的。如 1 字节(byte)是 8 比特(bit),一个 ASCII 字符占用 1 字节的内存(8 bit),下表描述了常见的数据量的单位。
| 2 的幂 | 近似值 | 全称 | 缩写 |
|---|---|---|---|
| 1000 | 1 Kilobyte | 1KB | |
| 1,000,000 | 1 Megabyte | 1MB | |
| 1,000,000,000 | 1 Gigabyte | 1GB | |
| 1,000,000,000,000 | 1 Terabyte | 1TB |
2. 常见的操作耗时
| 操作名称 | 耗时 |
|---|---|
| 3Ghz CPU时钟周期 | 0.3 ns |
| 执行指令 | 1ns |
| 查询 L1 缓存 | 1ns |
| 查询 L2 缓存 | 3ns |
| 分支预测错误 | 5ns |
| L3缓存访问 | 12 - 40 ns |
| 互斥锁定/解锁 | 17ns |
| 查询内存 | 70-100ns |
| 用 Zippy 压缩 1KB 数据 | 10,000ns=10us |
| 通过带宽为 1Gb/s的网络发送 2KB 数据 | 20,000ns=20us |
| 从内存中顺序读取 1MB 数据 | 250,000ns=250us |
| 数据在同一个数据中心往返一次 | 500,000=500us |
| getPid系统调用 | 40 ns |
| fread/fwrite系统调用 | 60 - 100 ns |
| 主(内)存访问 | 70 - 100 ns |
| PCIe | 400-900 ns |
| 网卡 | 1 us |
| 上下文切换 | 1-3 us |
| SSD随机读 | 16 us |
| 单机房内网络 | 0.5 - 2 ms |
| 同城双机房光纤50KM | 2 - 5 ms |
| 机械磁盘 | 2 - 10 ms |
| 在硬盘中查找数据 | 10,000,000ns=10ms |
| 在网络中顺序读取 1MB 数据 | 10,000,000ns=10ms |
| 在硬盘中顺序读取 1MB 数据 | 30,000,000ns=30ms |
| 数据包从加尼福利亚和荷兰之间往返一次 | 150,000,000ns=150ms |
| 阿里云异地机房(北京-广东) | 50 - 100 ms |
| 4G | 60 ms |
| 3G | 120 ms |
| 卫星 | 800 ms |
| 重启电脑 | 90 s |
注: 1 ns=s, 1 us=s=1000 ns, 1 ms=s=1000us=1,000,000ns
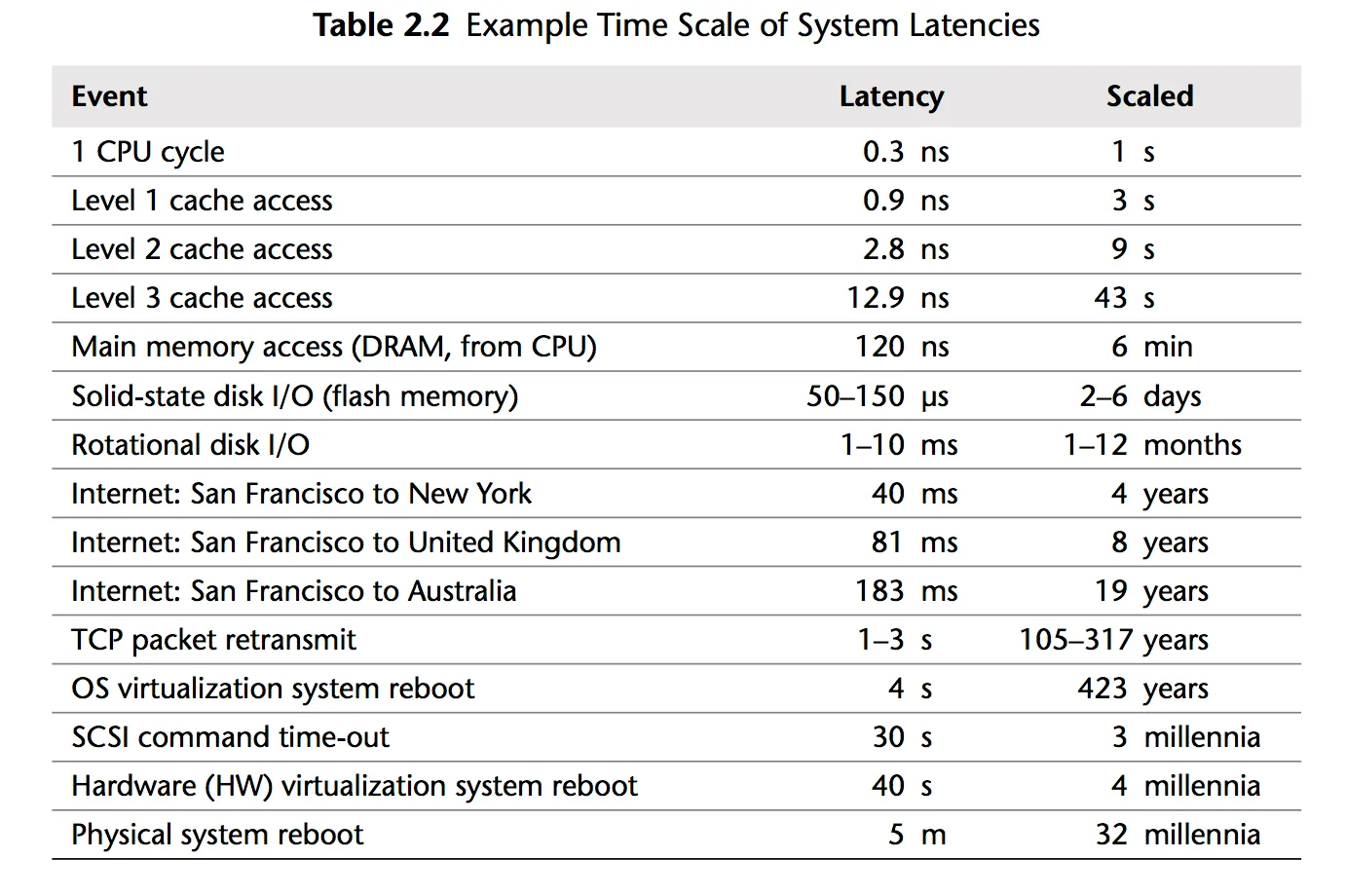
通过分析上述数据,我们可以得出如下结论:
- 内存的速度快,硬盘的速度相对较慢
- 如果有可能,经量避免在硬盘中查找数据
- 简单的压缩算法速度更快
- 尽可能将数据压缩之后在通过网络传输
- 数据中心常常位于不同地区,异地传输是需要时间
主流云厂商如腾讯云国内各机房延迟值
北京到上海:38ms
上海到广州:40ms
北京到广州:53ms
| 耗时 | 状态 | 感受 |
|---|---|---|
| 1~30ms | 极好 | 几乎察觉不出有延迟 |
| 31~50ms | 较好 | 没有明显延迟 |
| 51~100ms | 一般 | 有明显延迟 |
| >100ms | 差 | 丢包 ,掉线 |
3. 可用性相关数字
高可用性是指一个系统长时间持续运转的能力。高可用性一般是用百分比来衡量的,100% 意味着服务没有不可用时间。大部分服务的可用性在 99% 到 100% 之间。
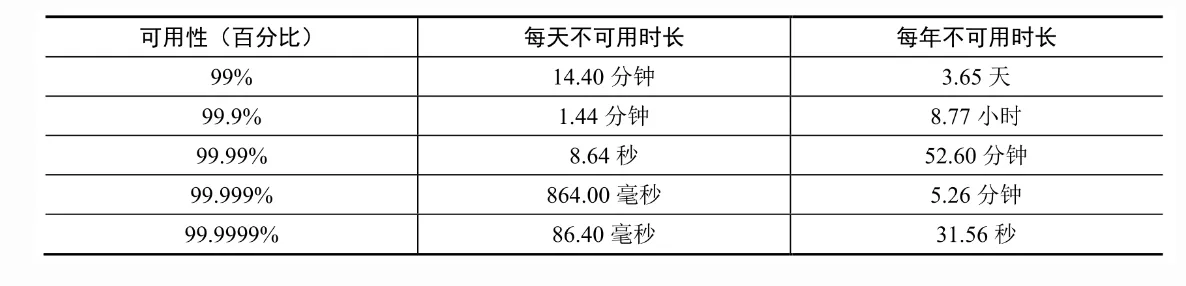
SLA(服务水平协议)是服务提供商普遍使用的一个术语。它是你(服务提供商)和你的客户之间的协议,正式规定了你提供的服务应该正常运行的时间。云服务提供商亚马逊、谷歌和微软把它们的SLA设定为99.9%或以上。正常运行时间通常是用小数点后“9”的个数来衡量的。“9”越多则代表可用性越高。下图列出了“9”的数量与系统预计不可用时长的关系。
4. 案例
下面来个小小的案例来尝试估算下系统的相关指标: 估算微博的QPS和存储需求
假设:
- 微博有 3 亿月活用户
- 50%的用户每天都使用微博
- 用户平均每天发两条微博
- 10%的微博包含多媒体数据
- 数据要存储5年
以下为根据上面的假设而估算出来的一些数据:
1)估算QPS(每秒查询量)
- 每日活跃用户(DAU)=300,000,000×50%=150,000,000
- 微博 QPS=150,000,000×2÷24小时÷3600秒≈3500
- 峰值QPS=2×推文QPS≈7000 2)这里仅估算多媒体数据的存储量
- 平均推文大小。
- weibo_id:64字节
- 文本:140字节
- 多媒体文件:1MB
- 多媒体数据存储量=150,000,000×2×10%×1MB=30TB/天
- 5年的多媒体数据存储量=30TB×365×5≈55PB
5. 总结
封底估算归根结底是考查过程的。解决问题的过程比获得结果更重要。面试官可能会测试你解决问题的技巧。这里提供几个小技巧。
- 凑整和近似。在面试中很难进行复杂的数学计算。比如,“99,987÷9.1”的结果是多少?没有必要花费宝贵的面试时间去解决复杂的数学问题,不需要算得很精确。尽可能凑整和使用近似数。例如前面的除法问题就可以简化为“100,000÷10”。
- 写下你的假设。写下所做的假设以便之后参考是个很好的主意。
- 标明单位。当你写下“5”时,它是代表5KB还是5MB?你可能会把自己搞糊涂。写明单位,比如“5MB”,就可以消除歧义。
- 面试中经常被问到的封底估算指标有:QPS、峰值QPS、存储大小、缓存大小、服务器的数量等。你可以在准备面试时练习这些指标的估算,熟能生巧。
非常感谢各位大佬能看到这里,最后希望大家都能早点下班,享受生活。

本文作者:CodeJump
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!